Thank you for this question! Let's consider the following program
I[1,1]: LV V6,0(R1)
I[2,1]: MULVS V8,V6,R4
I[2,2]: LV V10,0(R2)
I[3,1]: ADDV V10,V8,V10
I[4,1]: SV V10,0(R2)
Due to the data dependencies I[1,1]->I[2,1] (RAW on V6), I[3,1]->I[2,2] (RAW on V10) and I[4,1]->I[3,1] (RAW on V10), we get four convoys, which are given by the first index of each instruction.
First of all, recall that on slide 25, we agreed upon a pipeline architecture that has execution pipelines of the following lengths:
load/store 12
division 20
multiplication 7
others 6 If we do *not* have pipeline chaining, an instruction that has a conflict to a previous instruction must not be executed before its operands are *completely* available. Hence, (consider slide 38), when we send I[1,1] to an execution unit at time t=0, the first entry of its result vector leaves the execution pipeline at time 12 (since the load pipeline has 12 stages), and its final entry is leaving the pipeline at time l+11 where l is the length of the vectors. This is the earliest point of time where we can send I[2,1] to the execution pipeline so that the first entry of its result vector leaves the pipeline at time l+18 and the last entry leaves it at time 2l+17. Instruction I[2,2] does not have a dependency to I[2,1] and can therefore run in parallel to I[2,1], so that we can start it already at time t+12.
| start | first entry | last entry |
|---|
| I[1,1] | 0 | 12 | l+11 |
| I[2,1] | l+11 | l+18 | 2*l+17 |
| I[2,2] | l+12 | l+24 | 2*l+23 |
| I[3,1] | 2*l+23 | 2*l+29 | 3*l+28 |
| I[4,1] | 3*l+28 | 3*l+40 | 4*l+39 |
Now, what is changed if we have pipeleine chaining? Pipeline chaining means that we start the execution of an instruction already when the first entry is available and don't have to wait for the final entry. For the above example this means the following updates to slide 38:
| start | first entry | last entry |
|---|
| I[1,1] | 0 | 12 | l+11 |
| I[2,1] | 12 | 19 | l+18 |
| I[2,2] | 13 | 25 | l+24 |
| I[3,1] | 25 | 31 | l+30 |
| I[4,1] | 31 | 43 | l+42 |
As can be seen, the meaning of convoys, and thus their number does not matter much if we have pipeline chaining. The runtime using pipeline chaining is just determined by the vector length l (of course), and the (maximal) sum of the pipeline lengths that are chained up (note that the pipelines of I[2,1] and I[2,2] are not chained, they run in parallel).
To generalize all this by formulas, assume that we have convoys C[1],...,C[m] with instructions I[i,1],...,I[i,n[i]] in convoy C[i] and that the pipeline of instruction I[i,j] has q[i,j] many stages. Assuming that the execution of convoy C[i] starts at time t[i], then we get the following with or without pipeline chaining:
- I[i,j] starts at time t[i]+j-1
- the first entry of the result of I[i,j] leaves its pipeline at time t[i]+j-1+q[i,j]
- the last entry of the result of I[i,j] leaves its pipeline at time t[i]+j-1+q[i,j]+l-1
Without pipeline chaining, we have t[i+1] = t[i]+l-2+max{j+q[i,j] | j=1..n[i]}, i.e., convoy C[i+1] can start when the final entry of the last instruction of convoy C[i] is available. Solving the recursion yields t[k] = Q[k] - 2*(k-1) with Q[k] := sum{i=1..k-1} max{j+q[i,j] | j=1..n[I]}. Finally, that means that the runtime is t[m+1] which is in O(m*l+Q[m+1]).
With pipeline chaining, we have t[i+1] = t[I]-1+max{j+q[i,j] | j=1..n[I]} and solving this recursion yields t[k] = Q[k] - (k-1) with Q[k] := sum{i=1..k-1} max{j+q[i,j] | j=1..n[I]}. Finally, that means that the runtime is t[m+1]+l-1 which is in O(l-m+Q[m+1]). Essentially, pipeline chaining increases the runtime compared with the same processor without chaining by a factor of m, i.e., the number of convoys.
Note that these formulas only apply if there is no structural conflict. For instance, if we have only one functional unit for loading and storing and have to perform two independent load instructions, then we cannot schedule the second one right after the first one. Instead, the second one has to wait until the last address of the first component vector entered the pipeline. This structural conflict adds a vector length to a pipeline chain.
For instance, for vector length l=4, the example in the discussion below yields the following figure
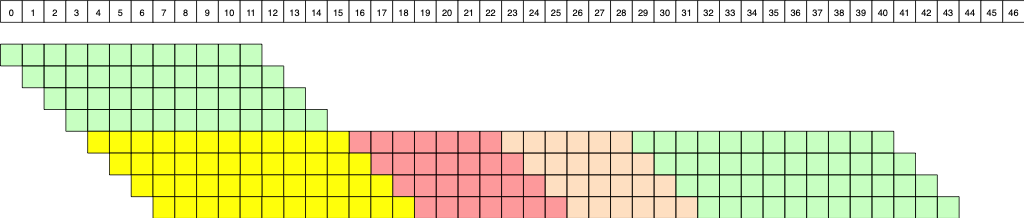
The runtime is then 4+12+7+6+12+4-1 = 44 and for l=64, we would have 64+12+7+6+12+64-1 = 164.