I have 2 questions regarding the following Kripke structure and 2 formulas:
vars a,b,c;
init 4,5;
labels 0:; 1:a; 2:a,b; 3:c; 4:a,c; 5:a,c; 6:;
transitions 0->4; 1->6; 3->4; 3->5; 4->2; 4->4; 4->6; 5->3; 6->0; 6->1; 6->3;
1) nu x. (a & <>x)
2) mu x. (!a | []x)
Both formulas result for inital state s4 in paths that I don't quite understand how the result is determined. Both basically boil down to:
1) true & (false | loop)
2) false | (true & loop)
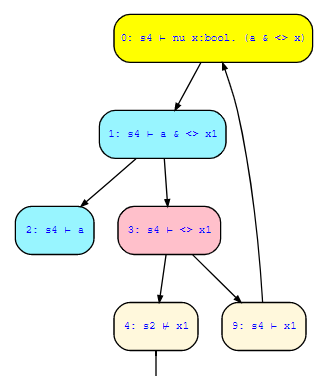
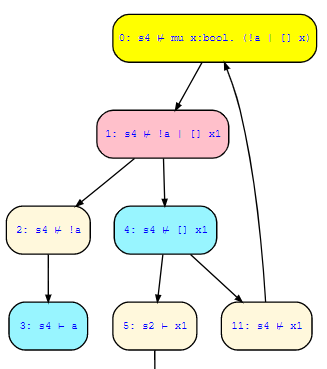
Where the loop just goes back to the same equation. To me it seems like both either loop forever or end in a false:
1) true & (false | loop) = (false | loop) = loop
2) false | (true & loop) = (true & loop) = loop
However, the first loop is evaluated as true, while the second is evaluated as false. How exactly is this determined?
Finally, I also noticed in the same examples that <>x without successors is evaluated as false, while []x without successors is evaluated as true. What is the intuition behind this? And how would <:>x and [:]x be evaluated if they don't have any predecessors?