Yes you are right. When we decode 0.66, we first identify that in the start interval [0.0,1.0], it belongs to B's sub-interval [0.6,0.8] (see first line in figure). Then in the interval [0.6,0.8], we identify that encoding 0.66 belongs to A's sub-interval [0.6,0.72] (second line in figure). Then in the interval [0.6,0.72], we narrow down 0.66 to A's sub-interval [0.6,0.672] (third line in figure). Continuing similarly, in the interval [0.6,0.672], encoding 0.66 belongs to C's sub-interval [0.6576,0.672] (fourth line in figure). As you can see, we may continue decoding like this forever since the number 0.66 will always belong to one of the sub-intervals.
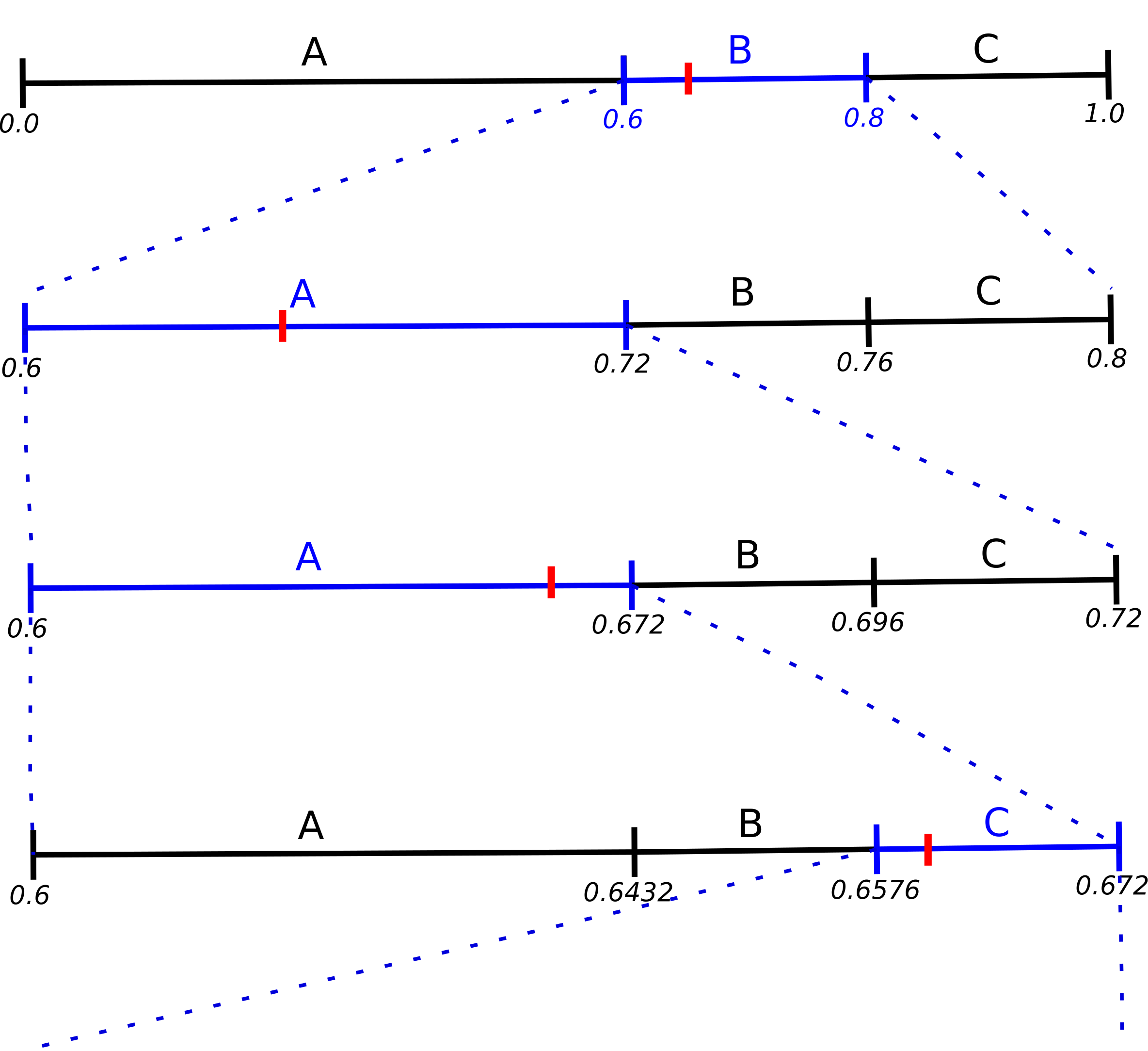
It is therefore necessary to inform the decoder when to stop. This can be done in a few ways. One way would be to use a special symbol as end-of-data. For instance, if symbol C is used in the above example to indicate end-of-data, the decoded word would be BAAC. Another way would be to specify total number of symbols in the word. For instance, if total number of symbols is specified as 5 in the above example, then the decoded word would be BAACA. In this case, there would be a fifth line in the above figure indicating that in the interval [0.6576,0.672], the encoding 0.66 belongs to A's sub-interval [0.6576,0.66624].